GPT-sovits=自定义AI语言模型训练
GPT-sovits=自定义AI语言模型训练
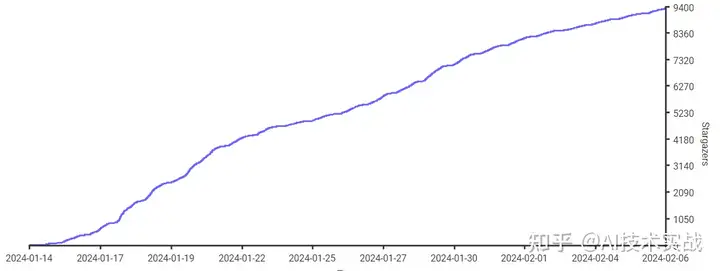
何平安GPT-SoVITS是一个开源的TTS项目,只需要1分钟的音频文件就可以克隆声音,支持将汉语、英语、日语三种语言的文本转为克隆声音,作者已测试,部署很方便,训练速度很快,效果很好。项目发布不到1个月就有了9.3k star。
直接看作者测试的效果,能够以假乱真了。
![]() 中文_原声.wav307.9K·百度网盘
中文_原声.wav307.9K·百度网盘![]() 中文_克隆声.wav262.4K·百度网盘
中文_克隆声.wav262.4K·百度网盘![]() 英语_克隆声.wav423.7K·百度网盘
英语_克隆声.wav423.7K·百度网盘![]() 日语_克隆声.wav979.2K·百度网盘
日语_克隆声.wav979.2K·百度网盘
GPT-SoVITS项目地址
https://github.com/RVC-Boss/GPT-SoVITS
以下是详细教程,阅读前请注意:
1.本文篇幅较长,截图较多,建议先收藏再阅读。
2.本文基于google colab运行,本地部署及autodl云端部署也可参考,基本相同。
3.如需本地一键安装包,可关注公众号”AI技术实战”,回复”声音克隆”获取。
1.部署运行
GPT-SoVITS提供了colab的notebook,并且提供了web-ui,可以一键部署,非常方便。点击下图中”COLAB”即可打开colab notebook。也可以直接打开链接:https://colab.research.google.com/github/RVC-Boss/GPT-SoVITS/blob/main/colab_webui.ipynb
进入colab笔记本,点击”全部运行”。

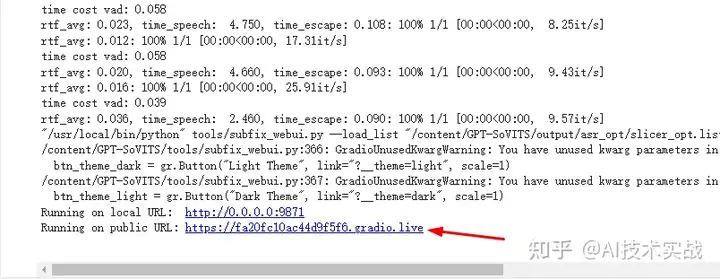
等待运行完成,需要等待10几分钟左右。

当看到日志出现Running on public URL时,说明启动成功,点击这个url,打开web界面

打开的web界面如下:

2.声音上传和处理
准备1分钟以上的干声音频文件用于训练,最好是在安静的环境下录制,如果音频文件中有背景声音或其他声音,则必须进行下面的处理,否则非必须,但是建议处理。
2.1 人声分离
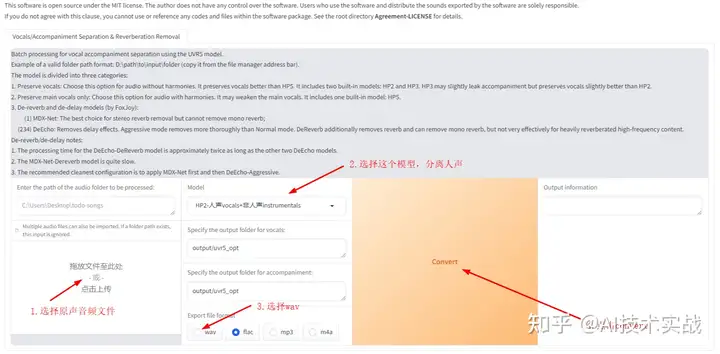
这一步操作是使用UVR5(一个处理声音的软件)提取出干净的人声,后面我们会使用提取出来的干声音频训练。进入界面,按下图选中Open UVR5-Webui。

在colab控制台会输出一个UVR5的web界面链接

打开这个链接,进入到UVR5的界面,按如下方式操作:
等待处理完成

处理成功

回到colab界面,按照如下路径打开,可看到人声已经被提取出来了

把instrument开头的文件删除,只保留人声
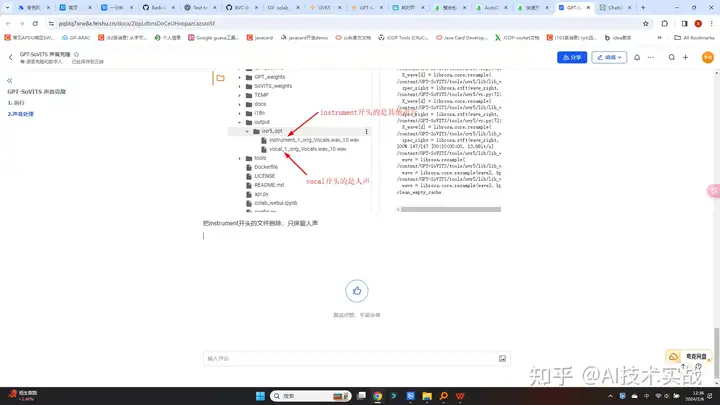
使用DeEchoAggressive把干声再处理一次,注意路径要写对。
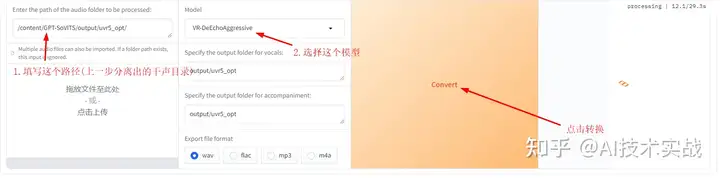
转换成功

下面箭头指的就是最终提取出的人声,把其他两个都删除,文件夹中只保留这一个文件。

干声提取成功后,UVR5的界面就可以关掉了,因为后面还会打开几个界面,担心不熟悉的朋友会懵,不关也可以。
2.2 切割音频
这一步要将干声音频切割,必须做,否则会爆显存。
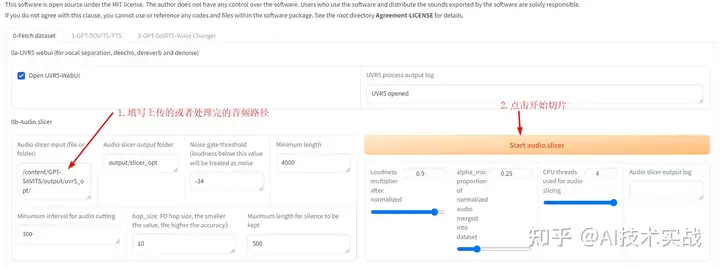
等待切割完成

回到colab页面,可以看到音频被切割为多个小段音频

2.3 打标
其实就是自动将输入的干声音频转为文字,用来告诉训练系统,音频中的哪个时间说的是什么字。注意输入的路径是上一步切割后的音频路径。
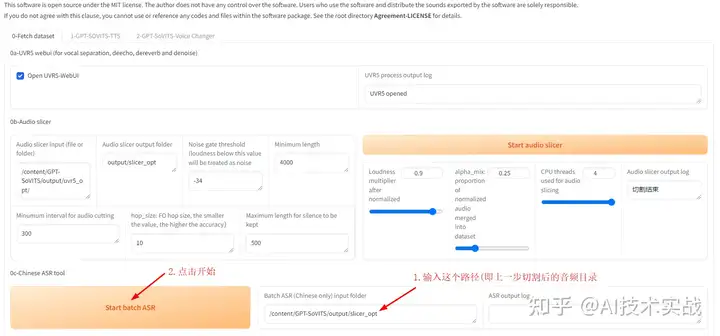
开始执行了

可以在colab控制台看到日志

稍等一会,在界面可以看到任务完成

在colab文件夹可以看到这个目录,.list文件就是自动打标生成的文件。

2.4 人工校对
因为上一步是自动做的,可能有些识别的不准,所以人工校对一下,追求完美可以校对,否则可以跳过这一步,系统自动识别的已经很准确了。

可以看到控制台又输出一个url,打开
以下是校对的web界面,列出了部分自动识别结果,可根据情况修改,这一步作者没做,有些功能不太清楚,读者有需要的话请自行研究。

3.训练
声音处理完成,终于要开始训练了。
3.1数据集格式化
进入界面,按照下图填写,还是要注意各路径要写对。

填写完成后,分别点击下面三个按钮,每个按钮点完后,等待执行结束再点击下一个。

3.2 SoVITS训练
填写模型名称,设置batch size,建议batch_size设置为显存的一半,高了会爆显存。
接着设置轮数(total epoch),SoVITS模型轮数(下图箭头4),可以设置的高一点,GPT模型轮数(下图箭头7)不能高于20(一般情况下)建议设置10。
点击”Start SoVITS training”(下图箭头5),注意点了箭头5之后,不要再点箭头7。
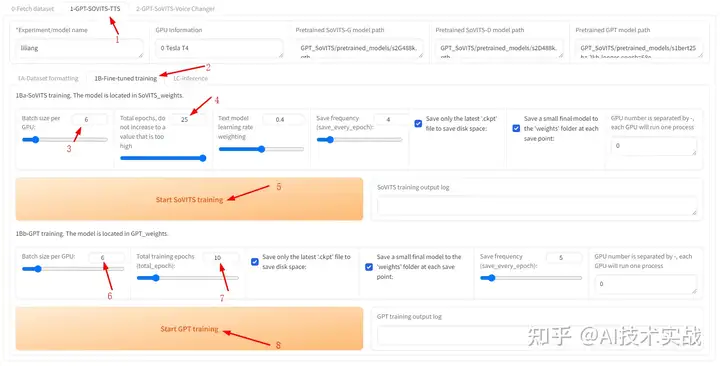
点击Start SoVITS traing之后,可以看到开始训练了。

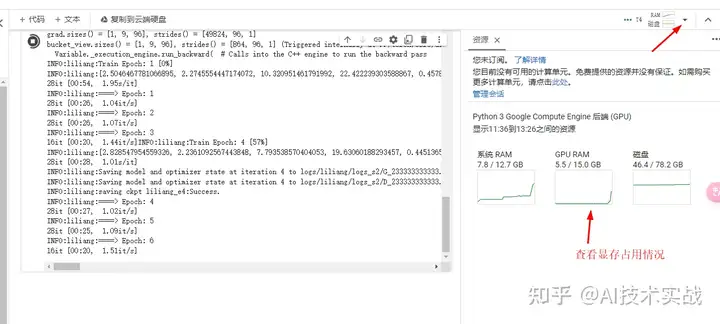
训练的时候可以查看显卡占用,爆显存了就调低batch size,或者存在过长的音频,需要在切割音频环节将过长音频再次切割。
SoVITS训练完成后会有提示。

可以看到SoVITS_weights目录中多了几个模型。
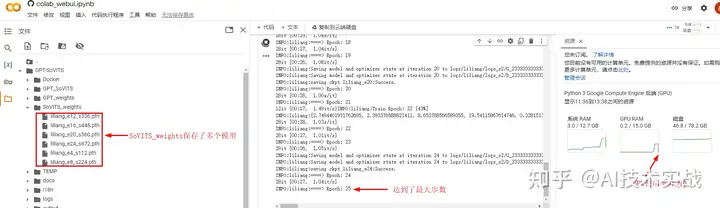
SoVITS训练完成,可以点击”Start GPT traing”开始GPT训练了,同样点完等待。

GPT也训练完成了。

4.推理
终于可以使用看效果了!推理又是另外一个界面了。
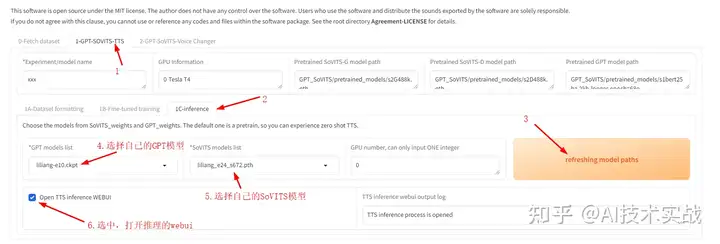
回到colab界面,可以看到又多了一个URL,打开这个URL

这个就是推理界面了。按照下图方式设置,开始文本转语音。

不出意外的话,稍等一会语音就合成好了,可以试听,也可以点击右边的三个小圆点下载到本地。

上面参考音频,建议是数据集中的音频。最好5秒。参考音频很重要!会学习语速和语气,请认真选择。参考音频的文本是参考音频说什么就填什么,必须要填。语种也要对应。
切分建议无脑选50字一切,低于50字的不会切。如果50字一切报错的话就是显存太小了可以按句号切。如果不切,显存越大能合成的越多,实测4090大约1000字,但已经胡言乱语了,所以哪怕你是4090也建议切分生成。合成的过长很容易胡言乱语。如果出现吞字,重复,参考音频混入的情况,这是正常现象。不是模型炼差了,不用为模型担心。改善的方法有使用较低轮数的GPT模型、合成文本再短点、换参考音频。官方也在努力修复这个问题。
5.保存模型用于以后推理
如果对模型比较满意的话,可以将模型保存下来,以后直接使用模型推理,不需要再浪费时间训练了。进入colab文件夹,按照下图方式下载即可。
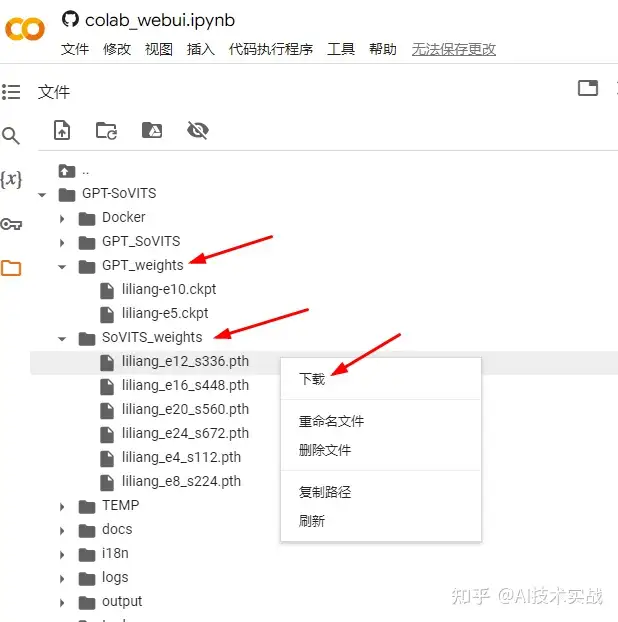
当然也可以保存到google云盘,这样下次使用colab的时候,可以直接从google云盘获取模型。下面是保存到google云盘的步骤。

上面点完之后,右边会自动多出挂载云盘的代码块,运行即可。

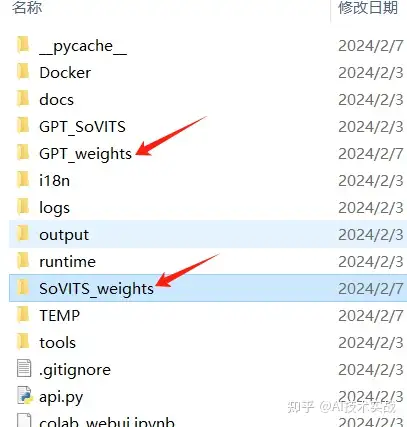
挂载成功之后,刷新左边的文件目录,可以看到drive文件夹,就是google云盘,可以将上面的GPT-SoVITS文件夹中的模型文件拖动到google云盘中。

以后需要推理时,将GPT模型(ckpt后缀)放入GPT_weights文件夹,SoVITS模型(pth后缀)放入SoVITS_weights文件夹,如下图所示,在界面中点击刷新模型,就可以使用这些模型进行推理了。
6.本地部署要求
训练:
1.Windows10/11系统,支持 CUDA 的8G以上显存的nVIDIA 显卡;
2.macOS 12.3或更高版本,搭载Apple芯片(M系列芯片)或AMD GPU的Mac(如2019款Mac Pro)
推理:
1.Windows10/11系统,支持 CUDA 的4G以上显存的nVIDIA 显卡;
2.macOS 12.3或更高版本,搭载Apple芯片(M系列芯片)或AMD GPU的Mac(如2019款Mac Pro)