HDFS YARN HDFS+YARN集群部署(何平安原创) 何平安 2024-11-26 2025-01-04 1.HDFS集群部署 选用的是Centos7的虚拟机,但是Centos的yum仓库不再支持了,本人自己写了文章如何使用新yum库:Centos不再支持服务了?新yum仓库+docker配置教程 | 天香园
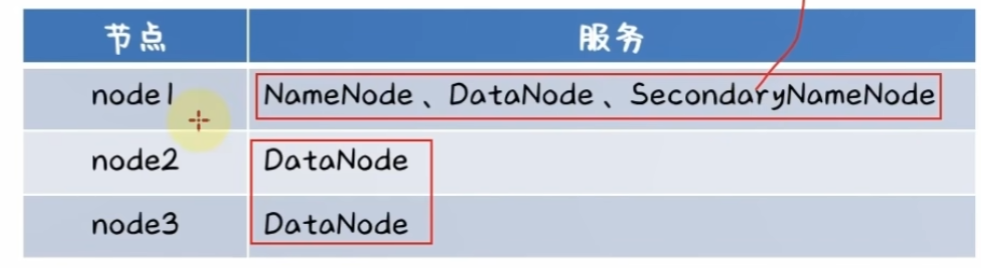
首先准备三台linux虚拟机,三台机子的角色如下:
上传hadoop安装包到node1,然后解压到/export/server/
1 2 3 4 5 6 bash tar -zxvf hadoop-3.3.4.tar.gz -C /export/server bash cd /export/serverln -s /export/server/hadoop-3.3.4 hadoopcd hadoop
下面是Hadoop安装包的各个结构的介绍
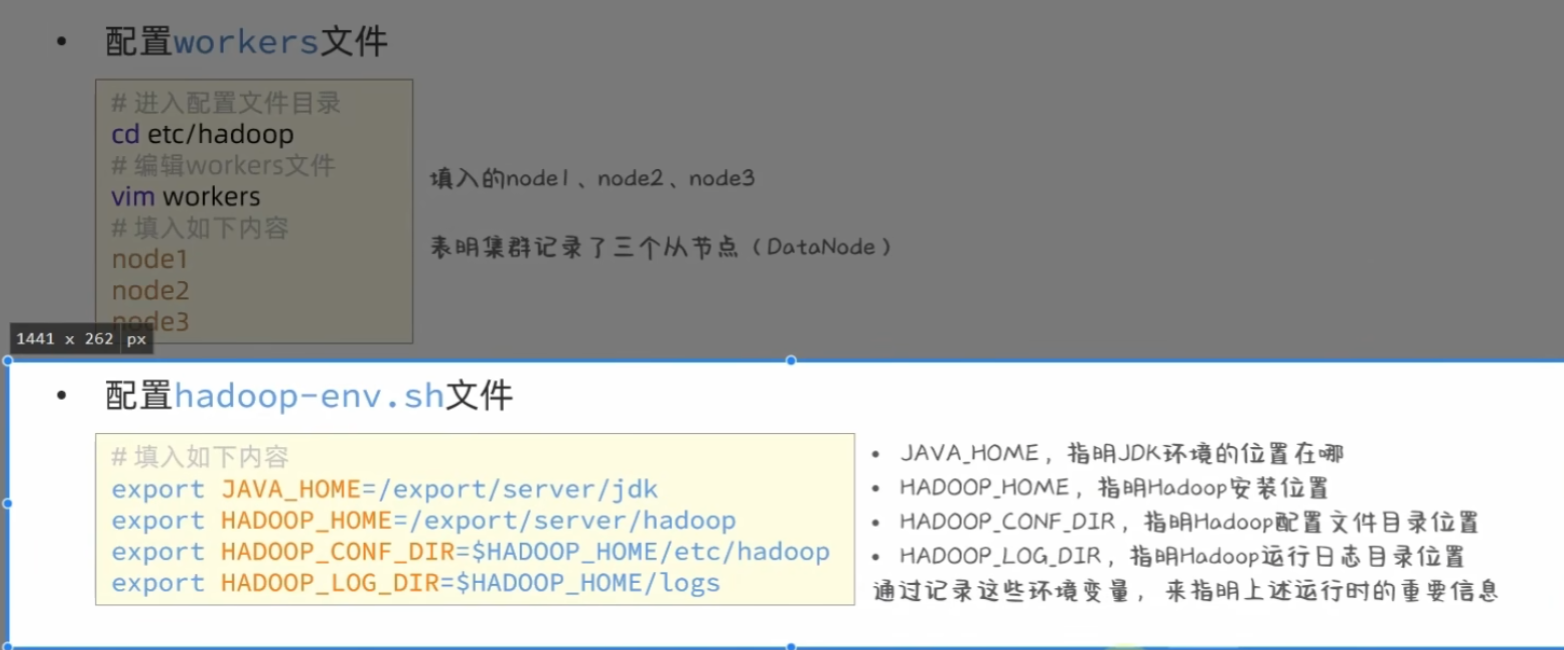
workers文件配置
1 2 cd /export/server/hadoop/etc/hadoopvim workers
由于我已在系统上定义了node1,2,3的ip地址指向,故直接写入node1/node2/node3即可
配置hadoop-env.sh:
1 2 3 4 5 export JAVA_HOME=/export/server/jdkexport HADOOP_HOME=/export/server/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME /etc/hadoopexport HADOOP_LOG_DIR=$HADOOP_HOME /logs
core-site.xml配置:
1 2 3 4 5 6 7 8 9 10 11 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://node1:8020</value > </property > <property > <name > io.file.buffer.size</name > <value > 131072</value > </property > </configuration >
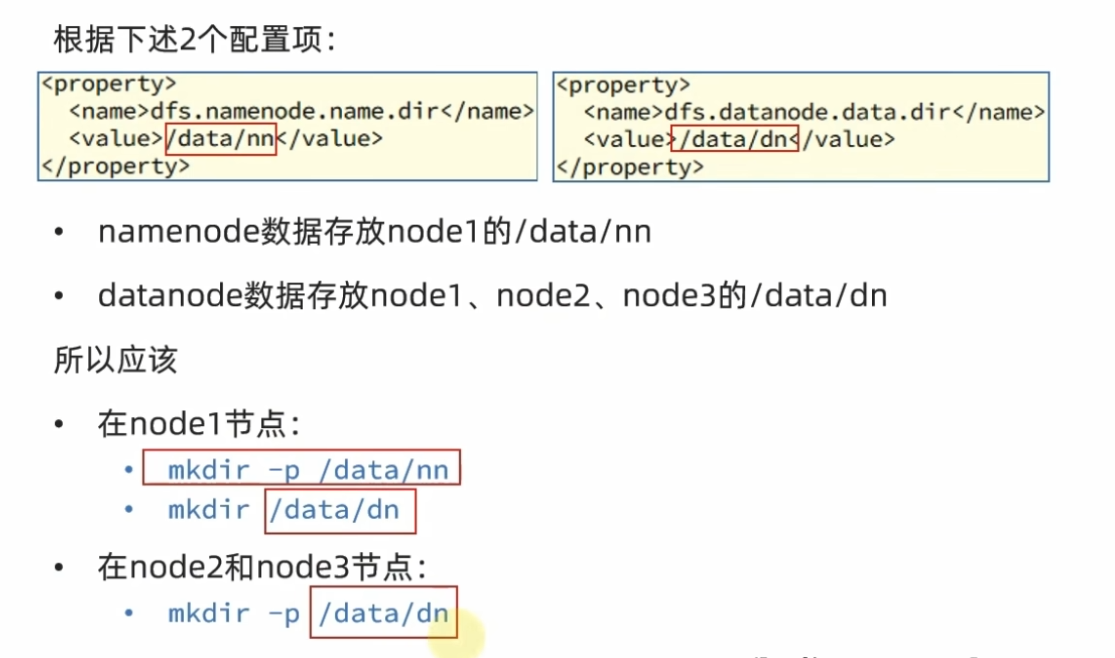
hdfs-site.xml配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 xml <configuration > <property > <name > dfs.datanode.data.dir.perm</name > <value > 700</value > </property > <property > <name > dfs.namenode.name.dir</name > <value > /data/nn</value > </property > <property > <name > dfs.namenode.hosts</name > <value > node1,node2,node3</value > </property > <property > <name > dfs.datanode.data.dir</name > <value > /data/dn</value > </property > <property > <name > dfs.namenode.handler.count</name > <value > 100</value > </property > <property > <name > dfs.blocksize</name > <value > 268435456</value > </property > </configuration >
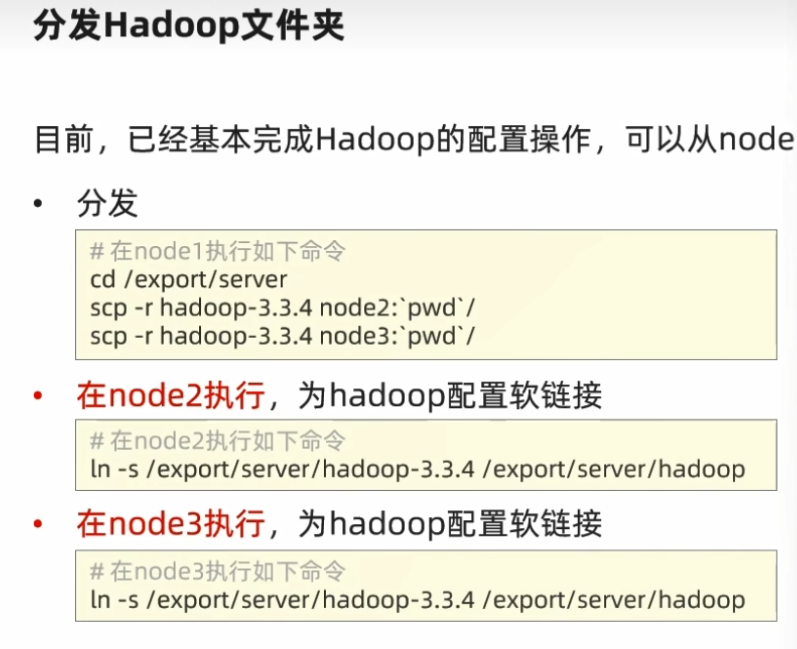
复制node1到node2,node3
1 2 3 cd /export/serverscp -r hadoop-3.3.4 node2:`pwd `/ scp -r hadoop-3.3.4 node3:`pwd `/
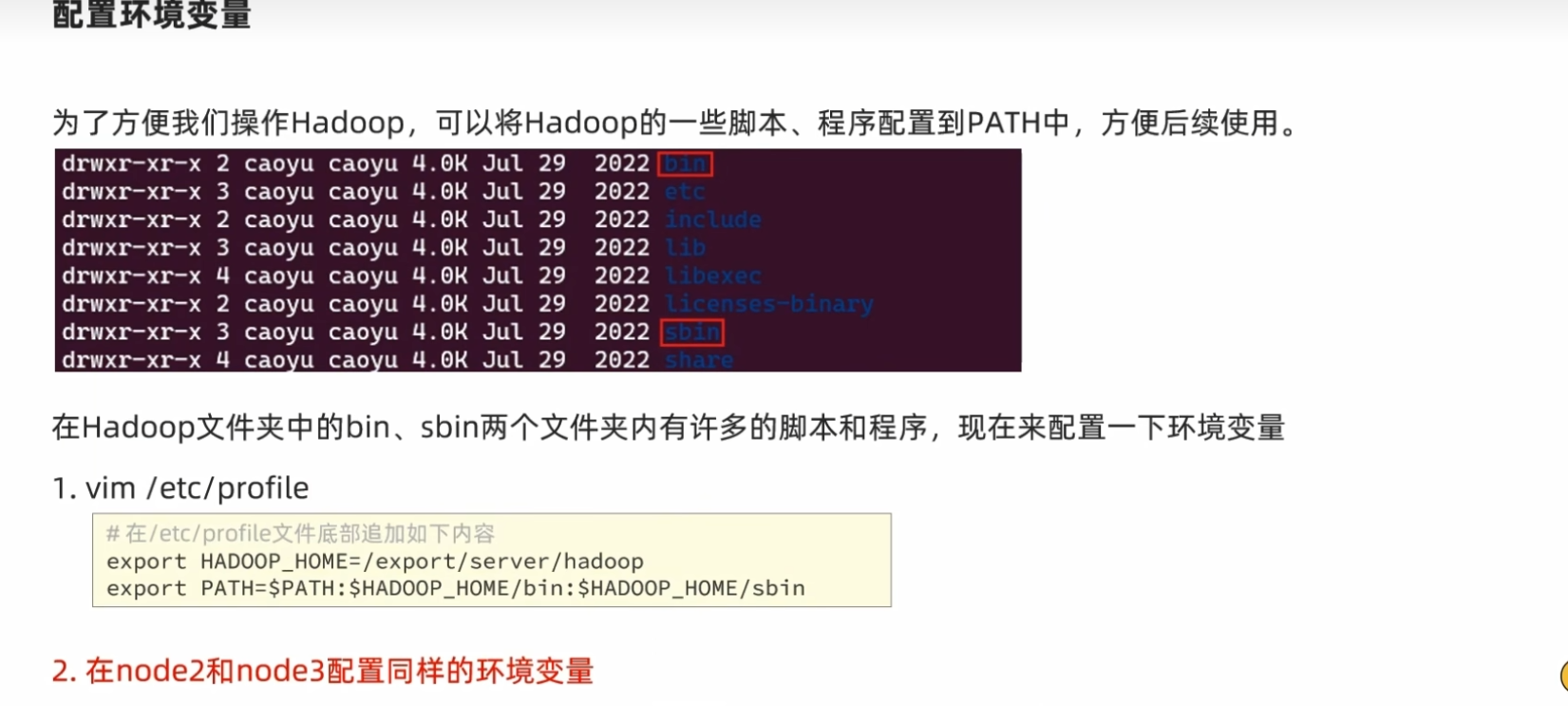
配置环境变量
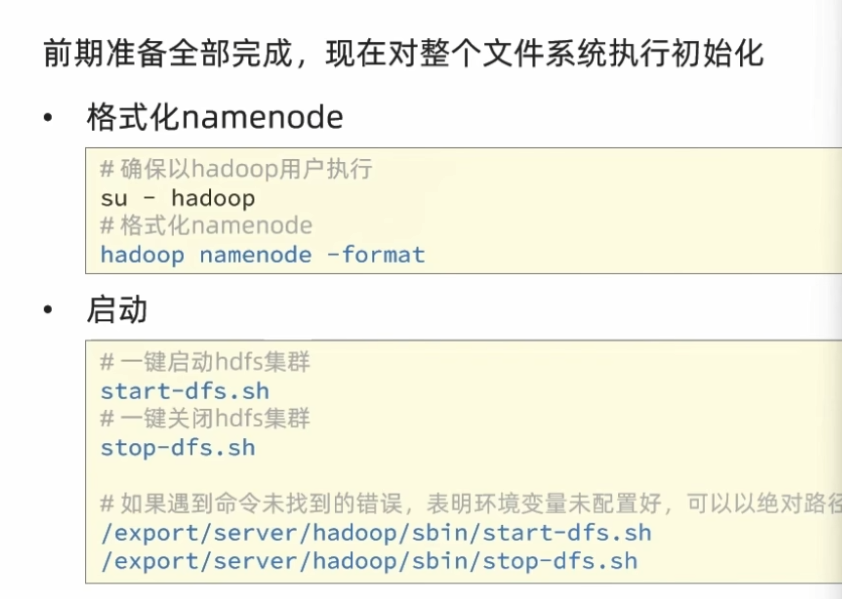
授权用户
1 2 3 su - hadoop start-dfs.sh
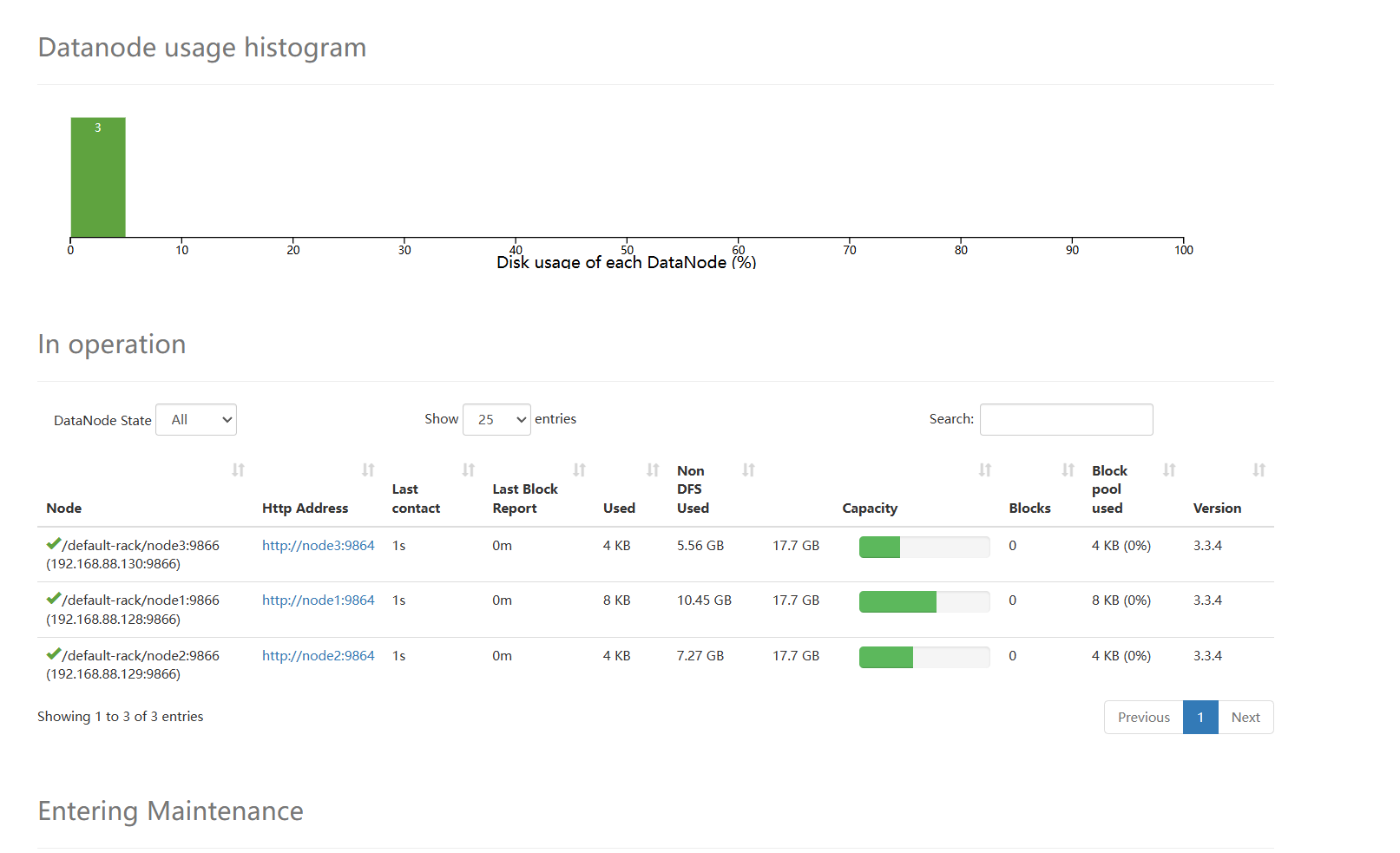
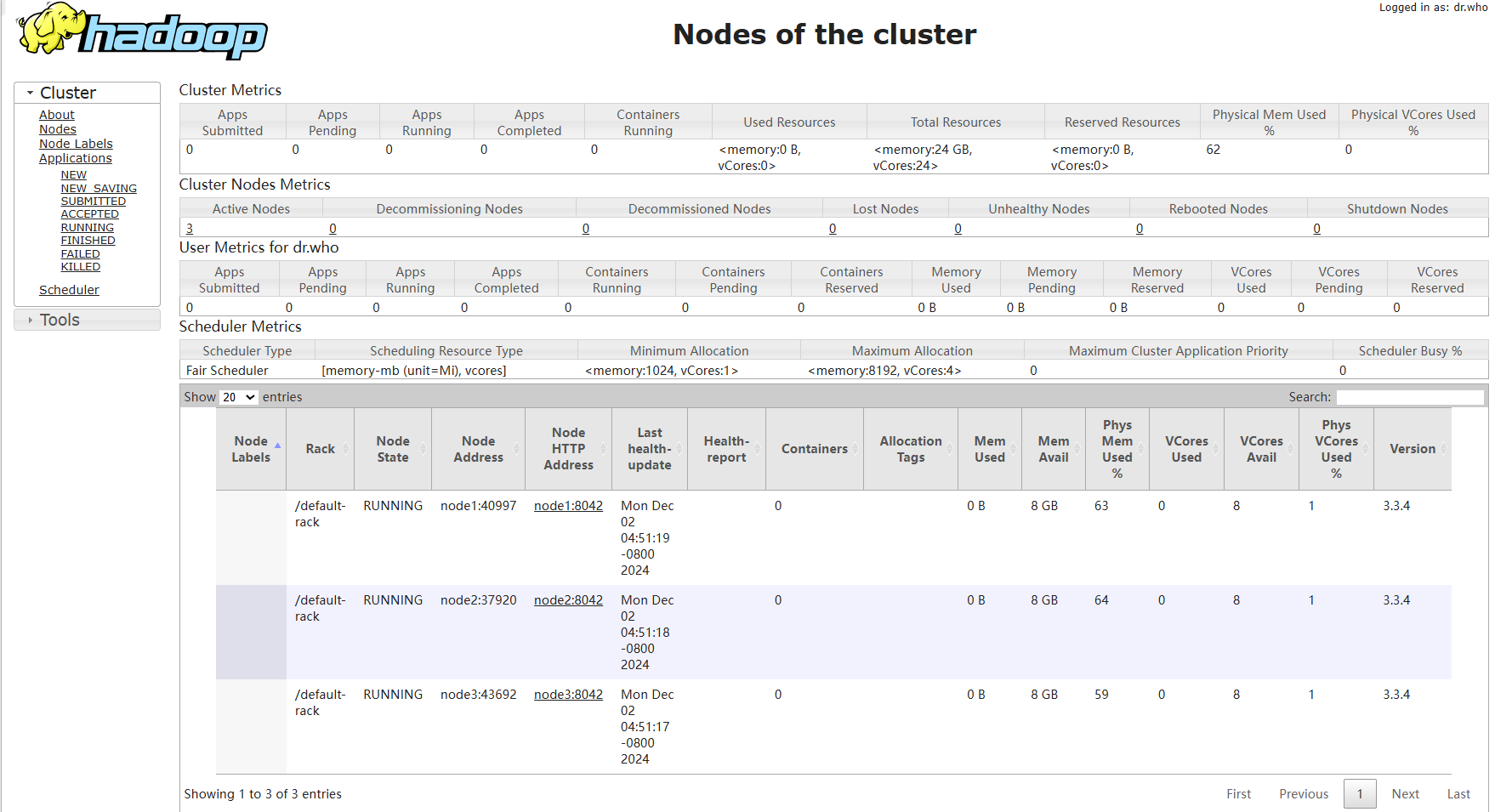
启动后可以浏览器输入node1:9870就可以访问hadoop页面了
当看到live nodes有3个时就证明配置成功了:
2.YARN集群部署 YARN的架构中除了核心角色,
即:ResourceManager:集群资源总管家
NodeManager:单机资源管家
还可以搭配2个辅助角色使得YARN集群运行更加稳定
代理服务器(ProxyServer):Web Application Proxy Web应用程序代理
历史服务器(JobHistoryServer): 应用程序历史信息记录服务
目前项目暂未用到YARN的计算,Java后端的数据处理比YARN集群的计算能力实力相当更简单,且YARN集群启动时所占用的内存空间很大,作为普通开发者通常没有大内存的服务器。
组件 配置文件 启动进程 备注
Hadoop HDFS
需修改
需启动NameNode作为主节点DataNode作为从节点SecondaryNameNode主节点辅助
分布式文件系统
Hadoop YARN
需修改
需启动ResourceManager作为集群资源管理者NodeManager作为单机资源管理者ProxyServer代理服务器提供安全性JobHistoryServer记录历史信息和日志
分布式资源调度
Hadoop MapReduce
需修改
无需启动任何进程MapReduce程序运行在YARN容器内
分布式数据计算
hadoop用户登录,cd /export/server/hadoop/etc/hadoop
mapred-env.sh文件,添加如下环境变量
1 2 3 4 5 export JAVA_HOME=/export/server/jdkexport HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
mapred-site.xml文件,添加如下配置信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > <description > </description > </property > <property > <name > mapreduce.jobhistory.address</name > <value > node1:10020</value > <description > </description > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > node1:19888</value > <description > </description > </property > <property > <name > mapreduce.jobhistory.intermediate-done-dir</name > <value > /data/mr-history/tmp</value > <description > </description > </property > <property > <name > mapreduce.jobhistory.done-dir</name > <value > /data/mr-history/done</value > <description > </description > </property > <property > <name > yarn.app.mapreduce.am.env</name > <value > HADOOP_MAPRED_HOME=$HADOOP_HOME</value > </property > <property > <name > mapreduce.map.env</name > <value > HADOOP_MAPRED_HOME=$HADOOP_HOME</value > </property > <property > <name > mapreduce.reduce.env</name > <value > HADOOP_MAPRED_HOME=$HADOOP_HOME</value > </property > </configuration >
yarn-env.sh文件,添加如下4行环境变量内容:
1 2 3 4 5 6 7 sh export JAVA_HOME=/export/server/jdkexport HADOOP_HOME=/export/server/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME /etc/hadoopexport HADOOP_LOG_DIR=$HADOOP_HOME /logs
yarn-site.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 xml <property > <name > yarn.log.server.url</name > <value > http://node1:19888/jobhistory/logs</value > <description > </description > </property > <property > <name > yarn.web-proxy.address</name > <value > node1:8089</value > <description > proxy server hostname and port</description > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > <description > Configuration to enable or disable log aggregation</description > </property > <property > <name > yarn.nodemanager.remote-app-log-dir</name > <value > /tmp/logs</value > <description > Configuration to enable or disable log aggregation</description > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > node1</value > <description > </description > </property > <property > <name > yarn.resourcemanager.scheduler.class</name > <value > org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value > <description > </description > </property > <property > <name > yarn.nodemanager.local-dirs</name > <value > /data/nm-local</value > <description > Comma-separated list of paths on the local filesystem where intermediate data is written.</description > </property > <property > <name > yarn.nodemanager.log-dirs</name > <value > /data/nm-log</value > <description > Comma-separated list of paths on the local filesystem where logs are written.</description > </property > <property > <name > yarn.nodemanager.log.retain-seconds</name > <value > 10800</value > <description > Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > <description > Shuffle service that needs to be set for Map Reduce applications.</description > </property >
再复制配置到node2,node3:
常用的进程启动命令如下:一键启动YARN集群:
1 $HADOOP_HOME /sbin/start-yarn.sh
会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager
会基于workers文件配置的主机启动NodeManager
一键停止YARN集群:
1 $HADOOP_HOME /sbin/stop-yarn.sh
在当前机器,单独启动或停止进程
$HADOOP_HOME/bin/yarn –daemon start|stop resourcemanager|nodemanager|proxyserver
start和stop决定启动和停止可控制resourcemanager、nodemanager、proxyserver三种进程
历史服务器启动和停止
1 $HADOOP_HOME /bin/mapred –daemon start|stop historyserver
node1:8088里点击nodes出现这种就成功了