Java集合类型汇总笔记
Java集合类型汇总笔记
何平安常见集合类型:
| 需求场景 | 推荐集合 |
|---|---|
| 查多改少、随机访问 | ArrayList |
| 频繁头尾增删(队列 / 栈) | LinkedList/ArrayDeque |
| 去重、无序 | HashSet |
| 去重、保留插入顺序 | LinkedHashSet |
| 去重、排序 | TreeSet |
| 键值对、无序、高效 | HashMap |
| 键值对、有序 | LinkedHashMap/TreeMap |
| 多线程键值对 | ConcurrentHashMap |
| 优先级任务调度 | PriorityQueue |
| 高并发生产者 - 消费者 | LinkedBlockingQueue |
LinkedList双向链表列表
基于双向链表实现的 List 接口实现类,既可以当列表用,也能当队列、栈来用。
核心特性:
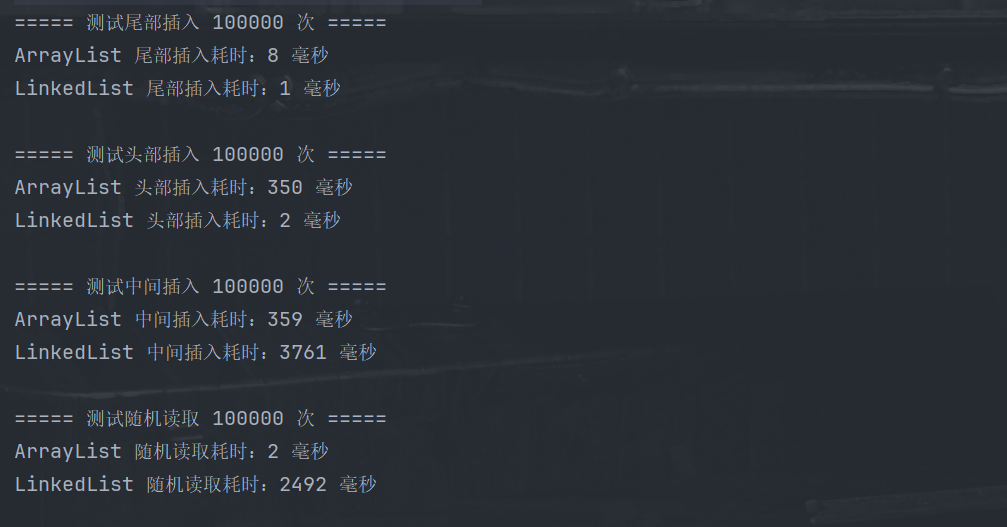
- 增删效率高:尤其是在链表头部 / 尾部,或已知节点位置时,增删只需修改节点引用,时间复杂度 O (1);但在指定索引增删,需要先遍历找到对应节点,时间复杂度 O (n)。
- 查询效率低:无法像 ArrayList 那样通过索引直接定位元素,必须从头 / 尾遍历到目标位置,时间复杂度 O (n)。
- 非线程安全:多线程环境下直接使用会有并发问题,需手动加锁或使用
Collections.synchronizedList()包装。 - 允许存储 null 值。
可以先看看与ArrayList的区别
| 特性 | LinkedList | ArrayList |
|---|---|---|
| 底层结构 | 双向链表 | 动态数组 |
| 随机访问 | 慢(O (n)) | 快(O (1)) |
| 增删操作 | 头尾增删快(O (1)) | 尾部增删快,中间增删慢(O (n)) |
| 内存占用 | 每个节点多存前后引用,稍大 | 连续内存,有扩容预留空间 |
| 适用场景 | 频繁增删、队列 / 栈场景 | 频繁查询、少量增删场景 |
实际应用场景:
电商系统的「订单待处理队列」(比如订单支付后的异步处理流程),这个场景能完整体现 LinkedList 「头尾操作高效」的核心优势,也是很多中小项目中实际落地的方案。
在电商系统中,用户支付订单后,不会立刻同步处理所有后续逻辑(比如扣减库存、生成物流单、发送短信通知),而是会把订单信息放入异步处理队列,由专门的消费线程逐个处理。这个队列的核心需求是:
- 生产者(支付接口):不断往队列尾部添加待处理订单(入队);
- 消费者(处理线程):不断从队列头部取出订单处理(出队);
- 支持高频率的入队 / 出队,且订单量可能动态变化(几百到几万条)。
这个场景中,头尾操作是核心,且几乎没有随机读取 / 中间增删的需求,完全契合 LinkedList 的特性(如果用 ArrayList,头部出队时需要移动所有元素,订单量越大越卡)。
扩展: LinkedHashSet
底层实现:HashMap + 双向链表,在 HashSet 基础上增加了链表维护插入顺序。
核心特性:
- 有序(存储顺序 = 插入顺序)、不可重复;
- 效率略低于 HashSet(多了链表维护),但比 TreeSet 高;
- 非线程安全。
应用场景:需要去重且保留插入顺序(比如记录用户浏览记录,去重且按浏览顺序展示)
深度思考……
既然LinkedHashSet既可以记录顺序又可以去除重复值,那我新增一个重复数据后会将那个重复数据的位置改变为尾部索引吗?参考代码:
1 | LinkedHashSet<String> set = new LinkedHashSet<>(); |
答:输出的仍然是[1,2,3,4,5],而不是[1,3,4,5,2],因为LinkedHashSet是继承的Set中add()如果添加了重复数据则会返回false则不会发生任何操作;如果要实现这种”真浏览器”效果,直接加一个if(add(i)){set.remove(i);set.add(i);}就行~OwO
ConcurrentHashMap线程安全
专门用于高并发场景下的键值对存储,是 Hashtable 的替代方案,也是多线程环境中 HashMap 的 “安全版”。
ConcurrentHashMap 属于 java.util.concurrent 包,实现了 ConcurrentMap 接口(继承自 Map),核心定位是:
- 线程安全:支持多线程并发读写,不会出现 HashMap 多线程下的死循环、数据丢失问题;
- 高效:相比 Hashtable 的 “全表锁”,它用更细粒度的锁机制,并发性能提升数倍;
- 功能:和 HashMap 类似(存储 key-value、key 唯一、支持 null 以外的元素)。
| 特性 | ConcurrentHashMap | HashMap | Hashtable |
|---|---|---|---|
| 线程安全 | 是(细粒度锁) | 否 | 是(全表锁) |
| 锁机制 | JDK1.8:CAS + 分段锁(synchronized) | 无锁 | 方法级 synchronized(全表锁) |
| 允许 null 值 | 否(key/value 都不行) | 是(key 仅 1 个) | 否 |
| 并发性能 | 高(多线程可同时操作不同段) | 无并发安全 | 低(单线程独占锁) |
| 底层结构(JDK1.8) | 数组 + 链表 + 红黑树 | 数组 + 链表 + 红黑树 | 数组 + 链表 |
通过以下代码验证线程安全:
1 | /** |
TreeMap红黑树
先来看下红黑树的定义:
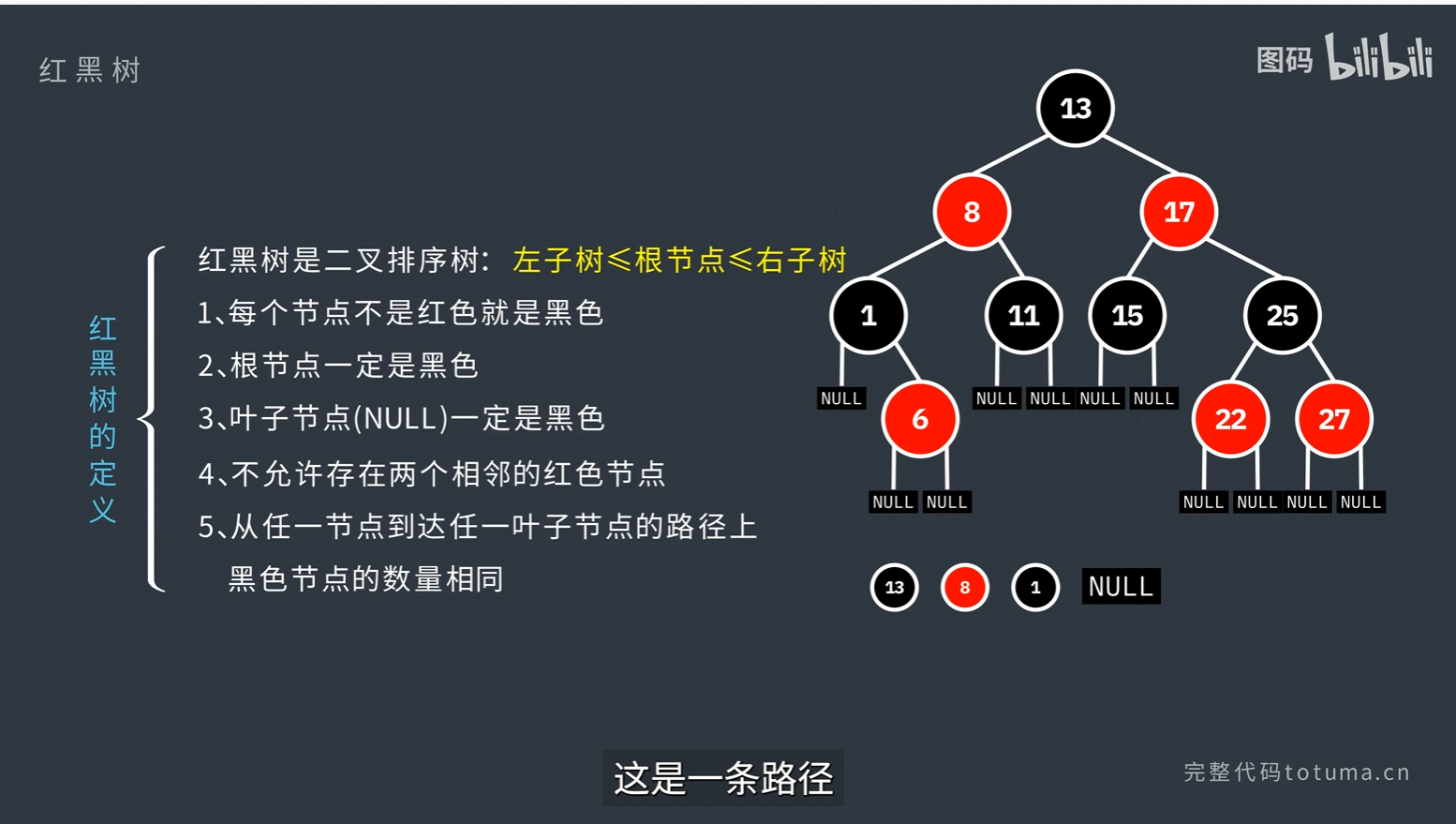
黑高bh要排除根节点;树高h—>最多节点(2^h) - 1
红黑树的特点:插入删除操作更高效
TreeMap 是基于红黑树(Red-Black Tree) 实现的 SortedMap 接口实现类,核心特性是键(key)有序(默认升序,可自定义排序规则),且键唯一,是处理 “有序键值对” 场景的核心工具。
其实就是拿来自动排序键值对的~
常用方法:
1 | // 1. 创建TreeMap(键为Integer,默认升序) |
- 获取key最小(第一个)的键值对
1 | scoreMap.firstEntry() |
- 获取key最大(末尾)的键值对
1 | scoreMap.lastEntry() |
- 获取key大于等于80的最小键值对
1 | scoreMap.ceilingKey(80) |
- 获取key小于90的最大键值对
1 | scoreMap.floorKey(90) |
- 获取key为80之后的最小键值对
1 | scoreMap.higherEntry(80) |
PriorityQueue优先级队列
核心特性是「队列中的元素会按优先级排序,每次出队(poll)的都是优先级最高的元素」
| 特性 | PriorityQueue(优先级队列) | LinkedList(普通队列) |
|---|---|---|
| 底层结构 | 二叉堆(默认小顶堆) | 双向链表 |
| 排序规则 | 按元素优先级(自然序 / 自定义) | 按插入顺序(FIFO) |
| 出队规则 | 优先级最高的元素先出队 | 先插入的元素先出队 |
| 访问队首 | O (1)(直接取堆顶) | O(1) |
| 插入 / 删除 | O (log n)(堆的调整) | O (1)(头尾操作) |
| 允许 null 元素 | 不允许(抛 NullPointerException) | 允许 |
| 线程安全 | 非线程安全 | 非线程安全 |
理解完全二叉树就知道PriorityQueue该怎么用了,下面举例说明:
1. 自然排序(默认小顶堆)
PriorityQueue 默认要求元素实现 Comparable 接口(如 Integer、String 等基础类型已实现),按自然顺序升序排列(小顶堆,堆顶是最小值)。
1 | import java.util.PriorityQueue; |
运行结果:
1 | 堆顶元素(最小值):1 |
2. 自定义排序(大顶堆 / 自定义规则)
如果需要大顶堆(堆顶是最大值),或元素是自定义对象,可在创建 PriorityQueue 时传入 Comparator 比较器。
示例 1:大顶堆(按整数降序)
1 | import java.util.Comparator; |
示例 2:自定义对象(按商品价格排序)
1 | import java.util.Comparator; |
运行结果:
1 | 按价格升序出队: |
PriorityQueue 的 API 与普通 Queue 基本一致,核心方法如下:
| 方法 | 作用 |
|---|---|
offer(E e) |
插入元素(堆自动调整,成功返回 true,元素为 null 抛异常) |
poll() |
移除并返回堆顶元素(优先级最高),队列为空返回 null |
peek() |
返回堆顶元素(不删除),队列为空返回 null |
isEmpty() |
判断队列是否为空 |
size() |
返回队列元素个数 |
clear() |
清空队列 |