FastPosition技术介绍

FastPosition技术介绍
何平安一份简历为您筛选全网最合适的岗位!
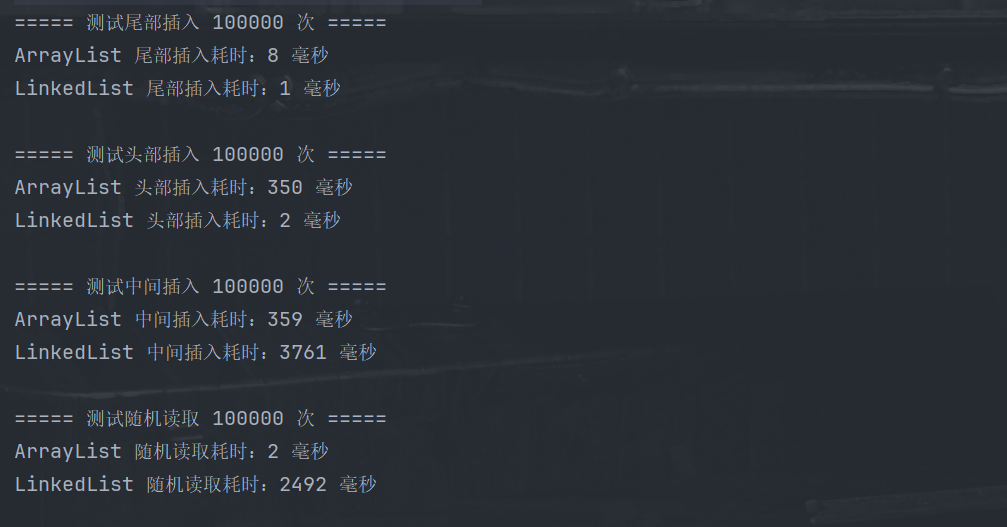
这里以qwen3.5:4b和qwen-embedding3:4b进行学习
既然要学习大模型应用那就直接用大模型应用来完成大模型应用,这里选用codex+trea双Vibe Coding工具进行开发,推荐安装MySQL和web research的MCP;
GitHub: hepingan11/FastPosition
数据爬取
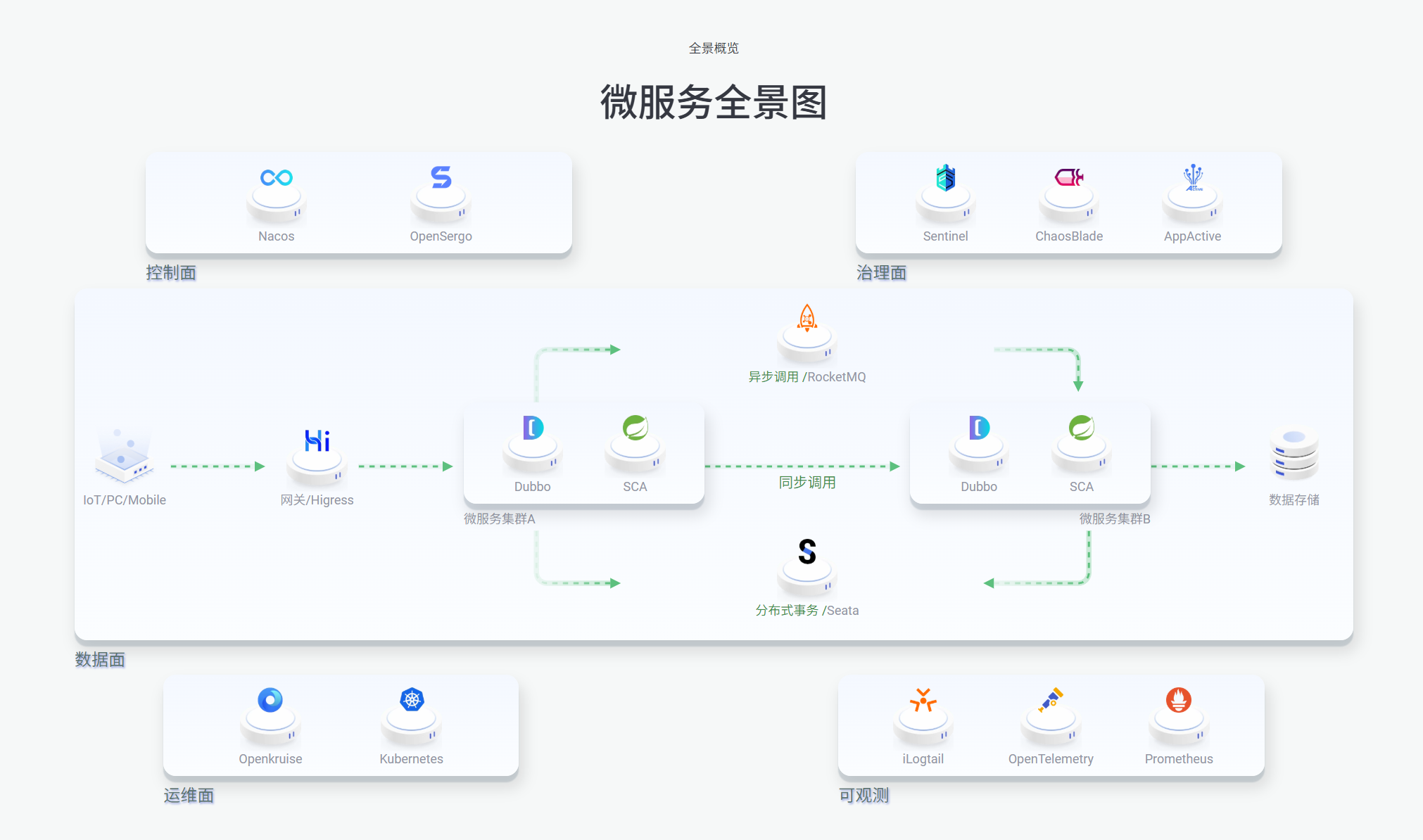
整个最难的就是职位的数据爬取,目前利用的是Playwright + LLM +接口匹配度算法 实现的
Playwright 很好说,因为职位信息网站里的数据大多都是动态的,爬取整个HTML太消耗token且定位不准,而Playwright 能直接定位查询接口获取完整的json数据;
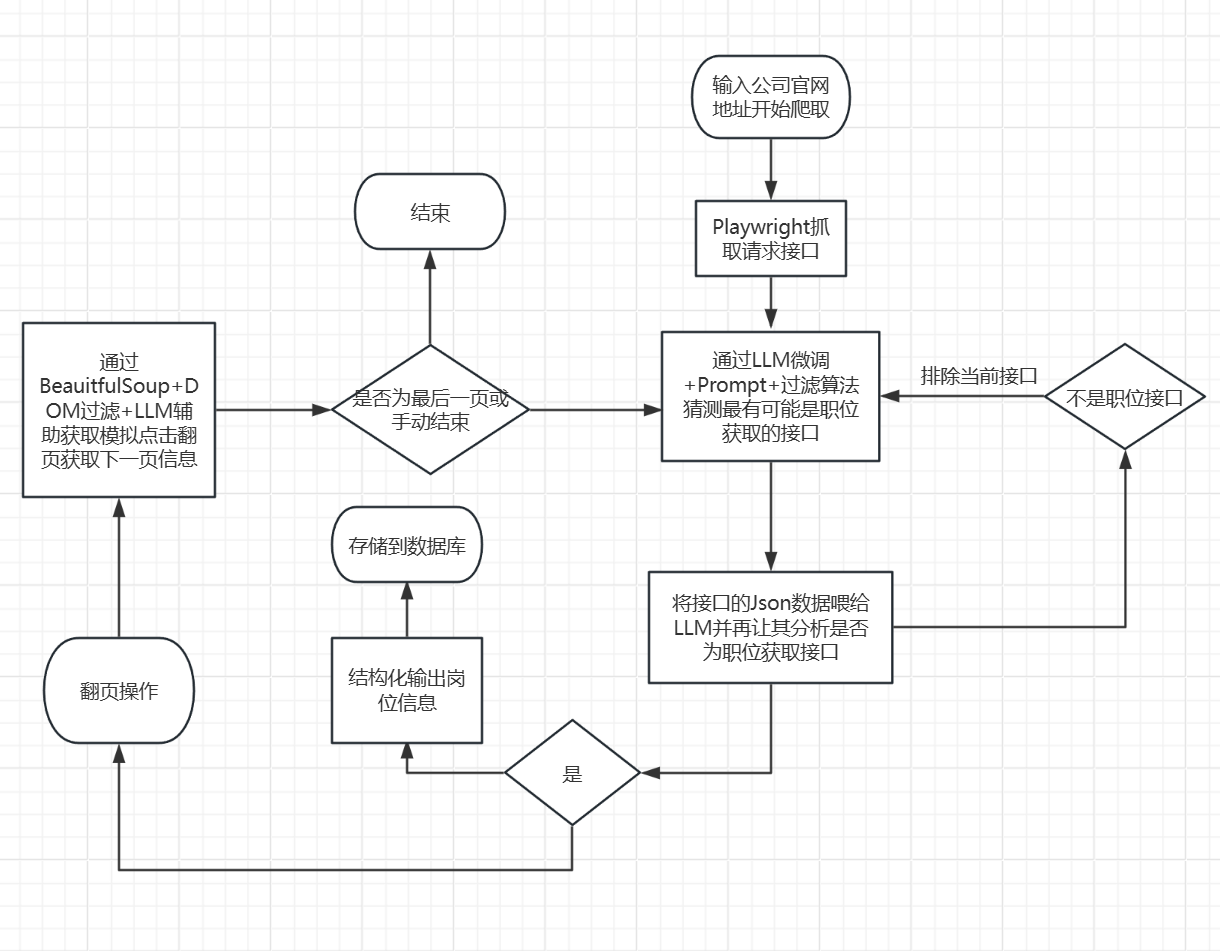
大致流程:
Playwright 打开页面并监听所有 JSON 响应, 代码在 fetch_page_payload()。它会:
- 打开招聘页
- 滚动页面
- 尝试翻页/加载更多
- 用 page.on(“response”, handle_response) 收集候选接口
规则初筛
代码在:is_rejected_api()
score_job_api_candidate()
URL 含 job/position/campus/recruit 才进候选
dictionary/city/workcities/family/filter 这类直接降权或排除
searchposition、/position/search 这类优先加分
结构判定
代码在:- extract_positions_from_json()
- normalize_job_item()
- looks_like_real_job_list()
它不会只看接口名,而是尝试从 JSON 里抽职位字段:
- name/title/positionName/postName
- location/city
- salary
- jd/description
- link/id
如果只能抽出“城市名/分类名”这种枚举项,没有职位特征,就判定不是职位接口。
LLM 复判
代码在 review_api_candidates_with_llm()。 它会把前几个候选接口的:- URL
- 规则分
- JSON 样本
交给 LLM 判断是不是职位接口,再做二次调分。 目前是“规则主导,LLM辅助”,不是完全交给 LLM。
最后如果 API 还是不可靠,才回退:
DOM 片段提取LLM 从页面片段里抽职位代码在 extract_positions() 和 prepare_crawl_result()。
你问“能不能让 LLM 先分析哪个是职位获取接口,再让 Playwright 去抓”,可以,但不建议放在第一步。 原因是 LLM 在不知道页面真实发了哪些请求前,根本没有足够信息判断。更合理的是现在这种顺序:
先用 Playwright 把页面真实请求抓出来,再让 LLM 在这些候选接口里做判断 ,也就是“LLM 选已发生的候选接口”,而不是“LLM 凭空猜接口”。
“职位获取接口匹配算法”主要在 app/services/job_crawler_service.py
职位匹配
用户上传 PDF 简历 → PDF 解析 + AI 提取简历结构化信息 → 简历 / 职位特征向量化 → 数据库相似度检索 → AI 深度匹配分析 → 前端展示高匹配职位(带匹配度 + 分析理由)
| 层级 | 技术选型 | 核心优势 & 适用场景 |
|---|---|---|
| PDF 解析 | PyMuPDF(fitz)+ pdfplumber | 轻量无依赖,解析速度快,能提取 PDF 文本 / 格式,适配各类简历 PDF(扫描件除外) |
| AI 信息提取 | 本地 Ollama(qwen2:7b/llama3:8b) | 全程本地运行,无 API 费用,精准提取简历结构化信息,适配不同简历排版 |
| 向量检索 | Chroma DB(轻量)/ Milvus(进阶) | Chroma 免部署、单文件运行,适合小体量数据;Milvus 适合后续职位数据量超 10 万条的场景 |
| 大模型嵌入 | Ollama 自带 Embedding(bge-small) | 复用本地模型,一键生成文本向量,无需额外部署嵌入模型,和匹配分析模型统一 |
| 数据库 | 原有 MySQL(存原始数据)+ 向量库 | MySQL 保留职位 / 简历原始信息,向量库做相似度检索,分工明确 |
| 后端接口 | FastAPI(首选)/ Flask | FastAPI 轻量、自动生成接口文档,异步性能好,和 Python 大模型 / 爬虫模块完美兼容 |
| 前端展示 | Streamlit(极简)/ Vue+ElementUI | Streamlit5 行代码做前端,无需前端知识,适合快速落地;Vue 适合后续做可视化升级 |
| AI 匹配分析 | 本地 Ollama(同提取模型) | 基于简历 + 职位信息做深度分析,输出匹配度 + 匹配理由 + 待提升点,比纯向量检索更精准 |